
Auger effect
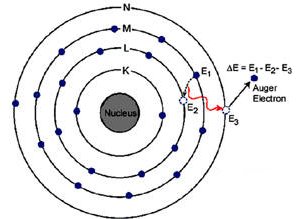
The Auger effect is the filling of a vacancy in an inner electron energy level in an atom by an electron from an outer energy level of the same atom. The excess energy involved causes emission of another electron known as an Auger electron. Auger electrons were discovered independently by Lise Meitner (in 1923) and the French physicist Pierre Victor Auger (in 1925), but the English-speaking scientific community attached Auger's name to the effect.
Auger electrons are produced when a sample is bombarded with electrons and a characteristic X-ray produced by inner shell ionization is reabsorbed, ejecting an electron. For example, a Si-Kα (K–L1) X-ray (energy of 1690 eV) may be emitted from a sample or transfer its energy to the L2,3 shell (binding energy ~70 eV), ejecting a Si KL1L2,3 Auger electron (energy 1620 eV).
Auger electron production is quantified by fluorescent yield, ω, which is the fraction of inner shell ionization that produce X-rays (thus, 1 – ω gives the fraction of Auger electrons). Auger electron have energies characteristic of their atom of origin, ranging from ~280 eV (C) to 2.1 keV (S). Given these low energies, Auger electrons only escape from the surface of a sample.

