
image
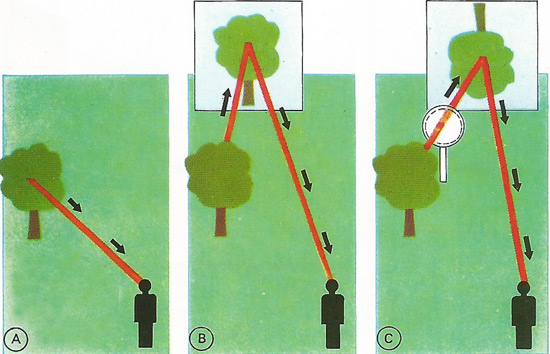
Images form when the eye receives light rays coming from the same point on an object and bends them to meet at the retina. The tree reflects light rays in all directions. The eye may see it directly [A], see a virtual image of the tree "behind" a mirror [B] or view a real image of it formed on a screen by a lens [C]. The images are located at the points from which the light rays appear to originate..
An image is a representation of an object formed by rays of light or other electromagnetic radiation in an optical instrument such as a telescope, microscope, or camera, or directly by the eye.
A real image has rays of light passing through it and is formed by points to which the rays from the object converge. Rays of light do not pass through the points composing a virtual image: the image lies at the place from which the light rays, if traced backwards, appear to diverge. A virtual image, such as that produced by a plane mirror, has no physical existence, whereas a real image can be projected onto screen and recorded, for example in the form of photographic emulsion.

